Zejście gradientowe, znane również jako gradient descent, to jeden z fundamentalnych algorytmów optymalizacyjnych w dziedzinie uczenia maszynowego i sztucznej inteligencji. Jego głównym celem jest minimalizacja funkcji kosztu, czyli funkcji, która mierzy, jak dobrze model radzi sobie z przewidywaniami w porównaniu do rzeczywistych danych. Bez efektywnego sposobu na dostosowanie parametrów modelu, uczenie maszynowe nie byłoby możliwe.
Czym jest funkcja kosztu i dlaczego chcemy ją minimalizować?
Funkcja kosztu (lub funkcja straty) kwantyfikuje błąd popełniany przez model. Wyobraźmy sobie, że budujemy model do przewidywania cen domów. Funkcja kosztu będzie obliczać różnicę między przewidywaną ceną a rzeczywistą ceną sprzedaży. Im większa ta różnica, tym wyższa wartość funkcji kosztu. Naszym celem jest takie dostrojenie wewnętrznych parametrów modelu (np. wag i odchyleń w sieci neuronowej), aby funkcja kosztu osiągnęła jak najniższą wartość. Minimalizacja tej funkcji oznacza, że model dokonuje coraz dokładniejszych przewidywań.
Jak działa zejście gradientowe?
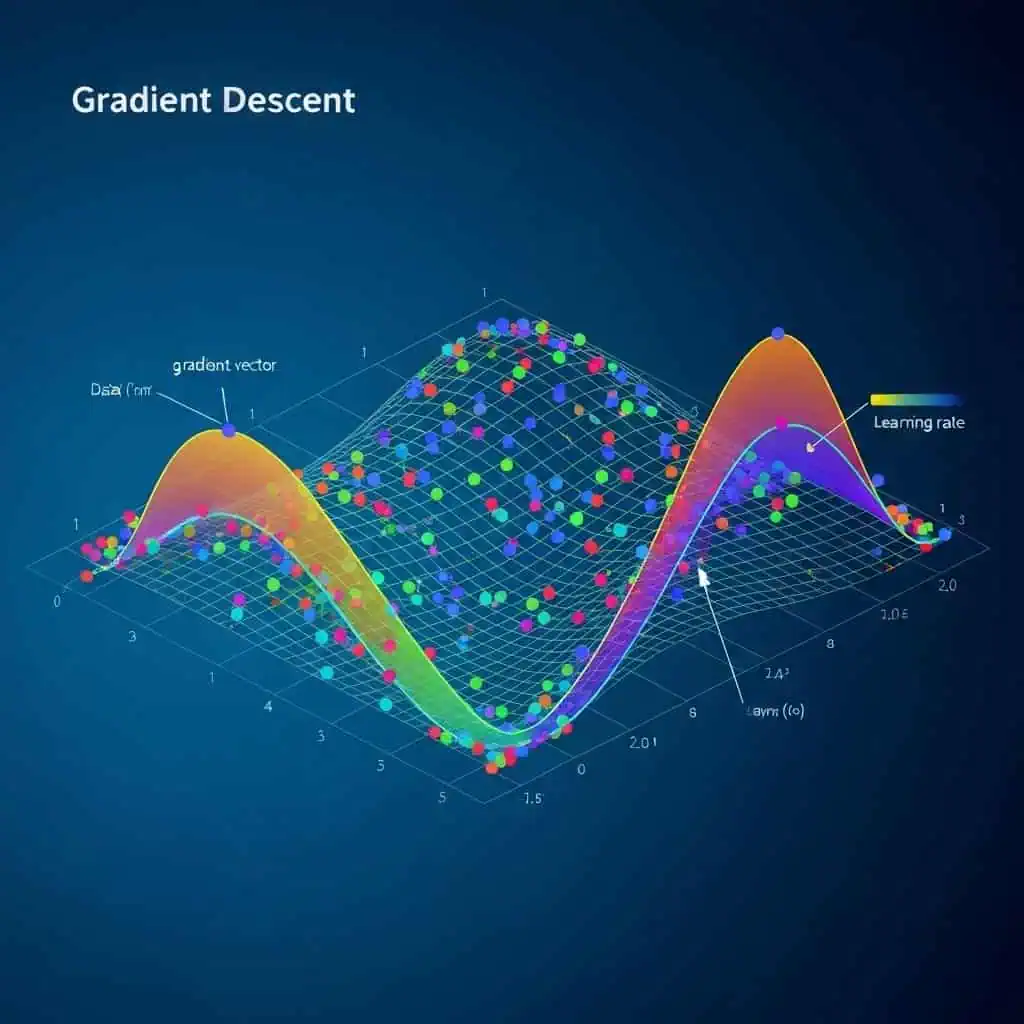
Podstawowa idea zejścia gradientowego polega na iteracyjnym poruszaniu się w kierunku najszybszego spadku funkcji kosztu. Kierunek ten jest określony przez gradient funkcji kosztu w danym punkcie. Gradient to wektor, którego składowe wskazują kierunek i wielkość największego wzrostu funkcji. Aby znaleźć kierunek najszybszego spadku, poruszamy się w kierunku przeciwnym do gradientu.
Proces ten można porównać do schodzenia z góry w gęstej mgle. Nie widzisz całego zbocza, ale możesz wyczuć, w którą stronę ziemia opada najszybciej. Robisz krok w tym kierunku, a następnie powtarzasz proces, aż dotrzesz do najniższego punktu.
Kluczowe elementy algorytmu: gradient i współczynnik uczenia
Dwa kluczowe elementy algorytmu zejścia gradientowego to gradient i współczynnik uczenia (ang. learning rate).
- Gradient: Jak wspomniano, gradient wskazuje kierunek największego wzrostu funkcji kosztu. Oblicza się go za pomocą pochodnych cząstkowych funkcji kosztu względem każdego parametru modelu.
- Współczynnik uczenia (alfa, α): To hiperparametr, który kontroluje wielkość kroku, jaki algorytm wykonuje w kierunku przeciwnym do gradientu. Zbyt duży współczynnik uczenia może spowodować „przeskoczenie” optymalnego punktu i niestabilność procesu uczenia. Zbyt mały z kolei może sprawić, że algorytm będzie zbiegał bardzo wolno, wymagając wielu iteracji do osiągnięcia zadowalającego rezultatu. Dobór odpowiedniego współczynnika uczenia jest kluczowy dla efektywności treningu modelu.
Różne warianty zejścia gradientowego
Istnieje kilka wariantów zejścia gradientowego, które różnią się sposobem wykorzystania danych treningowych w każdej iteracji:
1. Zejście gradientowe wsadowe (Batch Gradient Descent)
W tym wariancie, do obliczenia gradientu dla każdego kroku aktualizacji parametrów, wykorzystywany jest cały zbiór danych treningowych. Jest to podejście dokładne, ponieważ gradient jest obliczany na podstawie wszystkich dostępnych informacji. Jednakże, dla bardzo dużych zbiorów danych, obliczanie gradientu na całym zbiorze może być bardzo kosztowne obliczeniowo i czasochłonne.
2. Zejście gradientowe stochastyczne (Stochastic Gradient Descent – SGD)
SGD działa inaczej – w każdej iteracji aktualizuje parametry modelu na podstawie pojedynczego, losowo wybranego przykładu treningowego. To sprawia, że proces uczenia jest znacznie szybszy, zwłaszcza przy dużych zbiorach danych. Jednak ścieżka zbieżności jest bardziej „hałaśliwa” i może oscylować wokół minimum. Mimo tego, często jest wystarczająco dobra i jest szeroko stosowana.
3. Zejście gradientowe mini-wsadowe (Mini-Batch Gradient Descent)
Jest to hybrydowe podejście, które stara się połączyć zalety obu poprzednich metod. W tym wariancie, gradient jest obliczany na podstawie małej losowej podgrupy danych treningowych, zwanej „mini-wsadą” (mini-batch). Rozmiar mini-wsady jest hiperparametrem, który można dostosować. Mini-wsadowe zejście gradientowe jest najczęściej stosowanym wariantem w praktyce, ponieważ zapewnia równowagę między szybkością obliczeń a stabilnością zbieżności.
Wyzwania i rozwiązania w zejściu gradientowym
Jednym z głównych wyzwań w zejściu gradientowym jest utknięcie w lokalnych minimach. W przypadku funkcji kosztu, która nie jest wypukła, algorytm może zatrzymać się w punkcie, który nie jest globalnym minimum, ale jedynie lokalnym. W praktyce, szczególnie w sieciach neuronowych z wieloma parametrami, często można napotkać takie sytuacje.
Rozwiązaniem tego problemu mogą być różne techniki, takie jak:
- Momentum: Dodaje „pędu” do aktualizacji parametrów, pomagając algorytmowi „przetoczyć się” przez płytkie lokalne minima.
- Adam (Adaptive Moment Estimation): Jest to zaawansowany optymalizator, który adaptacyjnie dostosowuje współczynnik uczenia dla każdego parametru na podstawie pierwszych i drugich momentów gradientów. Adam jest obecnie jednym z najpopularniejszych i najskuteczniejszych optymalizatorów.
- Zmiana współczynnika uczenia w czasie (Learning Rate Scheduling): Stopniowe zmniejszanie współczynnika uczenia w trakcie treningu może pomóc algorytmowi zbiec się do minimum.
Zrozumienie i efektywne stosowanie zejścia gradientowego oraz jego wariantów jest kluczowe dla każdego, kto zajmuje się tworzeniem i trenowaniem modeli uczenia maszynowego.

